안녕하세요. 부앙입니다.
확통 공부를 하다가
문득 표본분산에 왜 분모에 n 대신 n-1을 쓰는지 궁금해졌습니다.
모분산은 분모에 n을 쓰지 않나요.
그럼 표본분산도 분모에 n을 쓰면 될텐데
왜 n-1을 쓰는 건지 궁금해졌습니다.
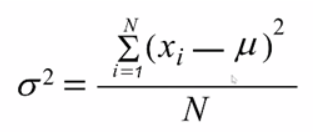
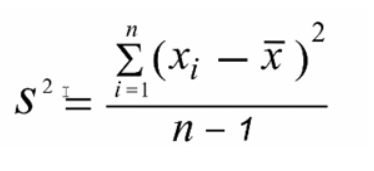
왼쪽: 모분산 공식/ 오른쪽: 표본분산 공식
왜 표본분산에선 분모가 n-1인지를 설명을 하기에 앞서
모분산은 모집단(예: 대한민국 전체 인구)의 분산이고,
표본분산은 표본집단(예: 대한민국 전체 인구 중 임의적으로 1000명 추출)의 분산임을 언급하고 갑니다.
표본분산은 왜 구하는 걸까?
질문에 대한 답을 하기 위해선 표본분산을 왜 구하는지부터 알아야 합니다.
표본분산을 구하는 이유는 모분산을 구하기 어려워서 표본분산을 대신 구하는 것입니다.
문장이 어렵게 느껴질 수도 있을 거 같아 하단에 예문을 덧붙여 봤습니다.
예) 대한민국 전체 인구의 평균 키의 분산을 구하는 것 = 모분산(모집단의 분산)
대한민국 전체 인구 중 1000명을 선발해서 평균 키의 분산을 구하는 것 =표본분산(표본집단의 분산)
대한민국 전체 인구의 평균 키의 분산값을 구하는 것은 어렵지만(모분산)
1000명을 선발해서 평균키의 분산값을 구하는 건 그나마 쉽습니다.(표본분산)
정리하자면 표본분산을 구하는 이유는
대한민국 전체 인구의 평균키의 분산값을 구하기가 어려우니까
표본분산(=대한민국 1000명의 키의 평균값의 분산)을 가지고
모분산(=대한민국 전체 인구의 평균키의 분산)의 값을 추측하려는 게 목표입니다.
그래서 n 대신 n-1을 대입하는 이유는 뭘까?
위에서 표본분산을 구하는 이유는 모분산의 값을 추측하기 위해서라고 언급했습니다.
즉 '표본분산 값 = 모분산 값' 과 똑같다란 보장이 없습니다.
대한민국 전체 인구(5천만명) 키의 평균의 분산값과
대한민국 인구 1000명의 키의 평균의 분산값은 같을 수 없습니다다.
근접할 수 있을진 몰라도.
즉 오차 범위가 생기기 마련인데 이 오차 범위를 어떻게 줄일 수 있을까?하고
학자들이 여러 차례 계산을 해본 끝에 밝혀낸 사실이 하나 있었습니다.
표본 분산의 분모에 n 대신 n-1을 대입하면
모분산의 값과 근접해진다는 사실이었습니다.
* 모분산의 값과 근접해진다 = 대한민국 전체 인구수의 평균 키의(분산) 값에 근접해진다.
* 표본분산의 값이 모분산의 값과 근접해진다. = 대한민국 인구 1000천명의 평균키(분산값)와 대한민국 전체 인구 수의 평균키(분산값)이 서로 근접해진다.
그래서 표본분산의 정확도(모분산의 값과 가까워지기 위해)
를 높이기 위해 분모에 n대신 n-1을 넣습니다.
생각보다 거창하거나 어려운 이유는 아니였습니다.
다시 한번 정리하자면 표본 분산에 n 대신 n-1을 넣는 이유는
학자들이 여러 차례 계산을 해보니 표본 분산의 분모에 n 대신 n-1을 대입해야 모분산의 값과 근접했었고,
그래서 표본분산을 구할 땐 분모에 n 대신 n-1을 넣는 것이 관행처럼 굳어졌다로 정리할 수 있습니다.
글이 조금이나마 도움이 되셨다면
하단의 공감(하트)을 눌러주시면 감사하겠습니다!
공감은 글을 쓰는 데 큰 도움이 됩니다!
'Math > 확률과 통계' 카테고리의 다른 글
| [확통] 조건부 확률, 곱셈 정리, 독립 사건이 뭘까? (0) | 2023.03.20 |
|---|---|
| [확통] 확률과 라플라스의 확률, 그리고 공리 (0) | 2023.03.09 |
| [확통] 표본공간이 무슨 뜻일까? (0) | 2023.03.09 |
| [확통] 왜 n!/(n-r)!은 nPr일까? (0) | 2021.12.31 |
| [확통] 왜 nPr(순열)에선 마지막에 n-r+1이 붙는 걸까? (0) | 2021.12.31 |